论文阅读-01
这篇是对《Simple Baselines for Human Pose Estimation and Tracking》这篇论文的阅读和理解笔记,其中不乏疏忽或误解之处,发现者还请指正。
摘要
在个人的理解中,这篇论文所做主要工作是为姿态估计(pose estimation)和姿态追踪(pose tracking)这2个研究领域各构建了一个架构简单,性能较高的基线模型。
PS:姿态估计和姿态追踪是什么:姿态估计是尝试从图像中推断出物体或人的姿势。这涉及识别和定位身体上的关键点,因此关键点检测是其中重要的一环。姿态追踪则是更进一步,在确定了姿态的基础上,于视频中实时跟踪人体姿态。
介绍
- 进行这项工作的原因:
- 随着姿态估计技术的迅速成熟,近年来提出了更具挑战性的“simultaneous pose detection and tracking in the wild”课题。
- 与此同时,网络体系结构和实验实践也日益复杂。这使得算法的分析和比较更加困难。
- 关于位姿跟踪,虽然目前还没有太多的研究,但随着问题维数和解空间的增加,系统的复杂度有望进一步提高。
- 这项工作是如何解决如上的问题的:
为这2个领域各提出了一个架构十分简单,但是性能却相对较高的模型,通过对基线模型的提出,人们在实验时可以更好的进行参照,同时由于模型架构简单,因此也可以更好的进行消融实验,从而更好的确定性能提高的关键因素。
PS:消融实验通俗的理解就是控制变量法,从而能够更好的找到性能提升的因素。
- 对于姿态估计的基线模型,论文所采用的是在ResNet的基础上添加一些反卷积层;对于姿态追踪的基线模型,则是基于ICCV'17 PoseTrack Challenge冠军的模型,添加基于光流的姿势传播和相似性测量,多人姿态追踪则额外添加了贪心匹配算法。
- 值得注意的是,这项工作没有任何理论依据。它以简单的技术为基础,并通过全面的消融实验进行了验证。我们不能与以前的方法进行全面和公正的比较,因为这是困难的,不是我们的意图。如上所述,这项工作的贡献是该领域的坚实基线。
姿态估计baseline
姿态估计的基线模型在ResNet的基础上,再继续接入若干个反卷积块,获取高分辨率的热图(c图所示)。
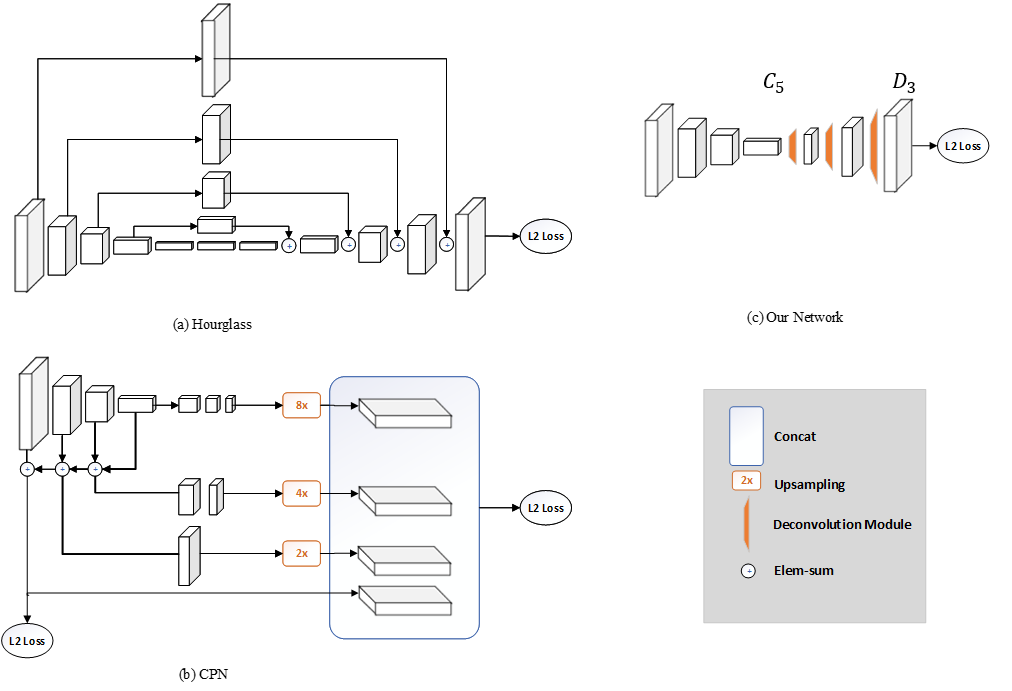
同时,论文也对当时主流的架构进行了少量的对比分析,作者认为他们的方法在生成高分辨率特征图方面与另外两种有所不同。两个流行的方案都使用上采样来提高特征映射的分辨率,并将卷积参数放入其他块中。相反,他们的方法将上采样和卷积参数以更简单的方式组合到反卷积层中,而不使用跳层连接。但由于以上方案都能得到较好的性能,因此作者认为得到高分辨率的特征图是十分必要的。
姿态追踪baseline
由于单人姿态跟踪与多人相比只是少了贪心匹配的环节,因此单人姿态估计这里就不再赘述,将注意力集中到多人姿态跟踪的任务当中去。
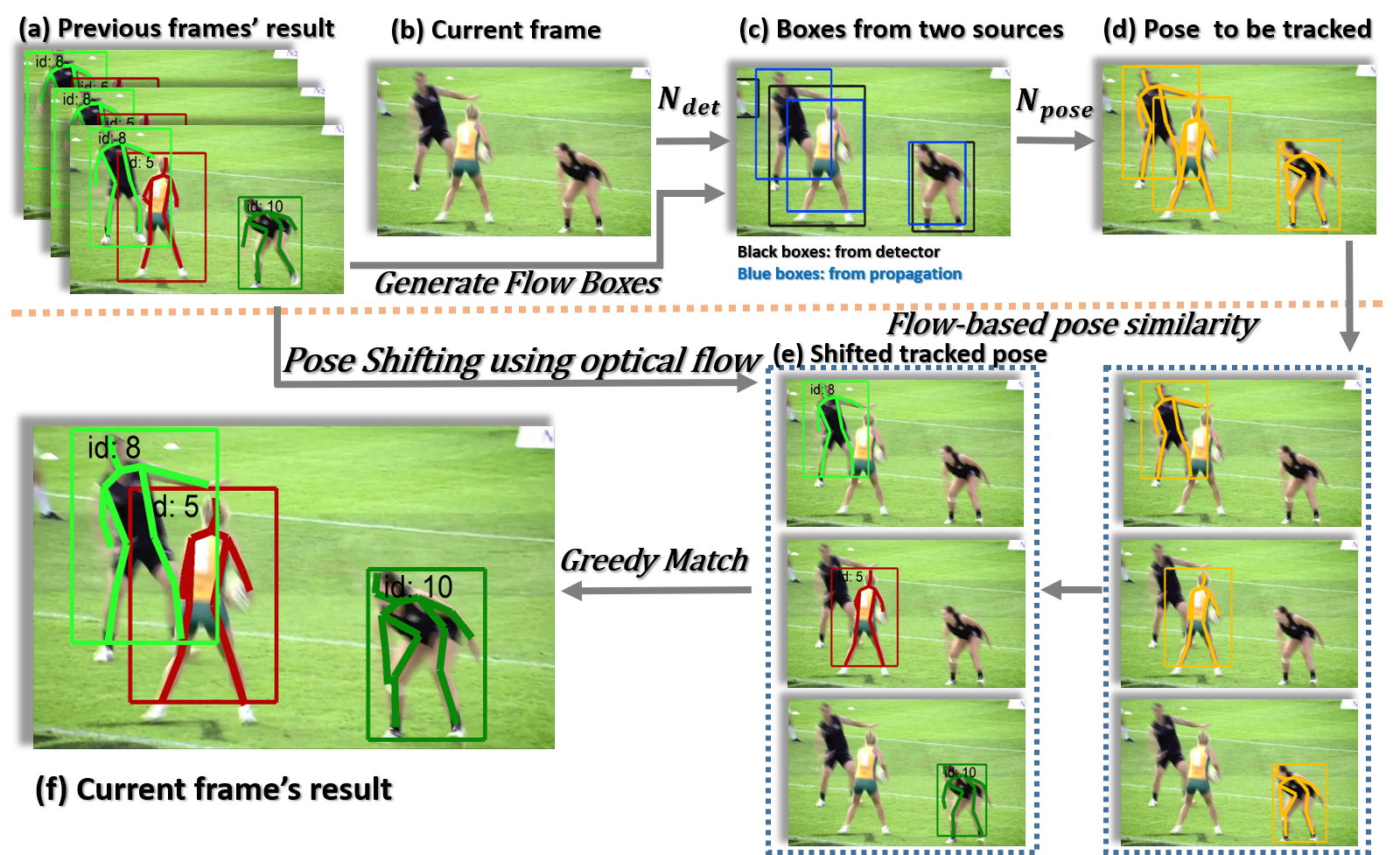
多人姿态跟踪任务可以拆分为:
- 步骤一:首先估计每帧中的人体姿势
- 步骤二:然后通过在帧间为其分配唯一的识别号id
- 步骤三:将不同帧的id进行关联匹配,完成跟踪
步骤一
步骤一的任务可以简化为对一张图片进行人物的检测识别,文中是基于R-CNN架构来进行的,首先回顾一下这个架构:
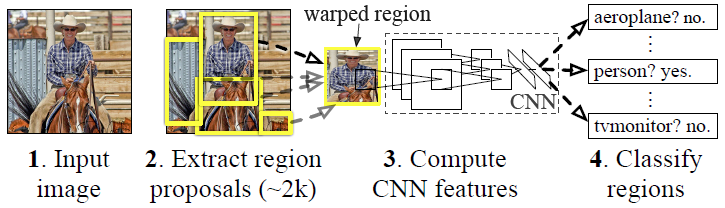
流程如下所示:
- 候选区域生成: 一张图像生成1K~2K个候选区域 (采用Selective Search 方法)
- 特征提取: 对每个候选区域,使用深度卷积网络提取特征 (CNN)
- 类别判断: 特征送入每一类的SVM 分类器,判别是否属于该类
- 位置精修: 使用回归器精细修正候选框位置
但是这种传统的方法作用于视频帧上面可能会出现由于视频帧引入的运动模糊和遮挡而导致检测缺失和错误检测的问题。
为此,我们需要对模型进行一定的修改。论文中不再采用传统的分割区域的方式,而是引入了两种不同的human box,一种来自人体探测器,另一种是使用optical flow(光流)从先前的帧中生成的box。人体探测器文中未显示的提及,故此处按下不表。而采用光流的方式则是充分利用时间信息,从附近的帧生成用于处理帧的方框。如:

由于我们有2种检测器,因此我们采用bbox非最大抑制(NMS)操作来统一来自人类探测器的box和使用optical flow从先前帧传播关节生成的box。由progagating joints产生的boxes作为检测器缺失检测的补充。
然后便通过我们提出的位姿估计网络,利用这些boxes对经过裁剪和调整大小的图像进行人体姿态估计。
步骤二
步骤二就比较简洁了,一一分配id即可,这边不再赘述
步骤三
步骤三中的关联匹配过程我们采用的是贪心匹配算法,即如下所示:

一般而言使用的相似度度量方式是使用边界框IoU(Intersection over Union)来进行。但用这种方式来链接实例可能会出现问题:当实例移动很快,因此框不会重叠,并且在拥挤的场景中,框可能与实例没有对应的关系。更细粒度的度量可以是姿势相似性,它使用对象关键点相似性(OKS)计算两个实例之间的身体关节距离。当同一个人的姿势因姿势变化而不同时,姿势相似性也会产生问题。
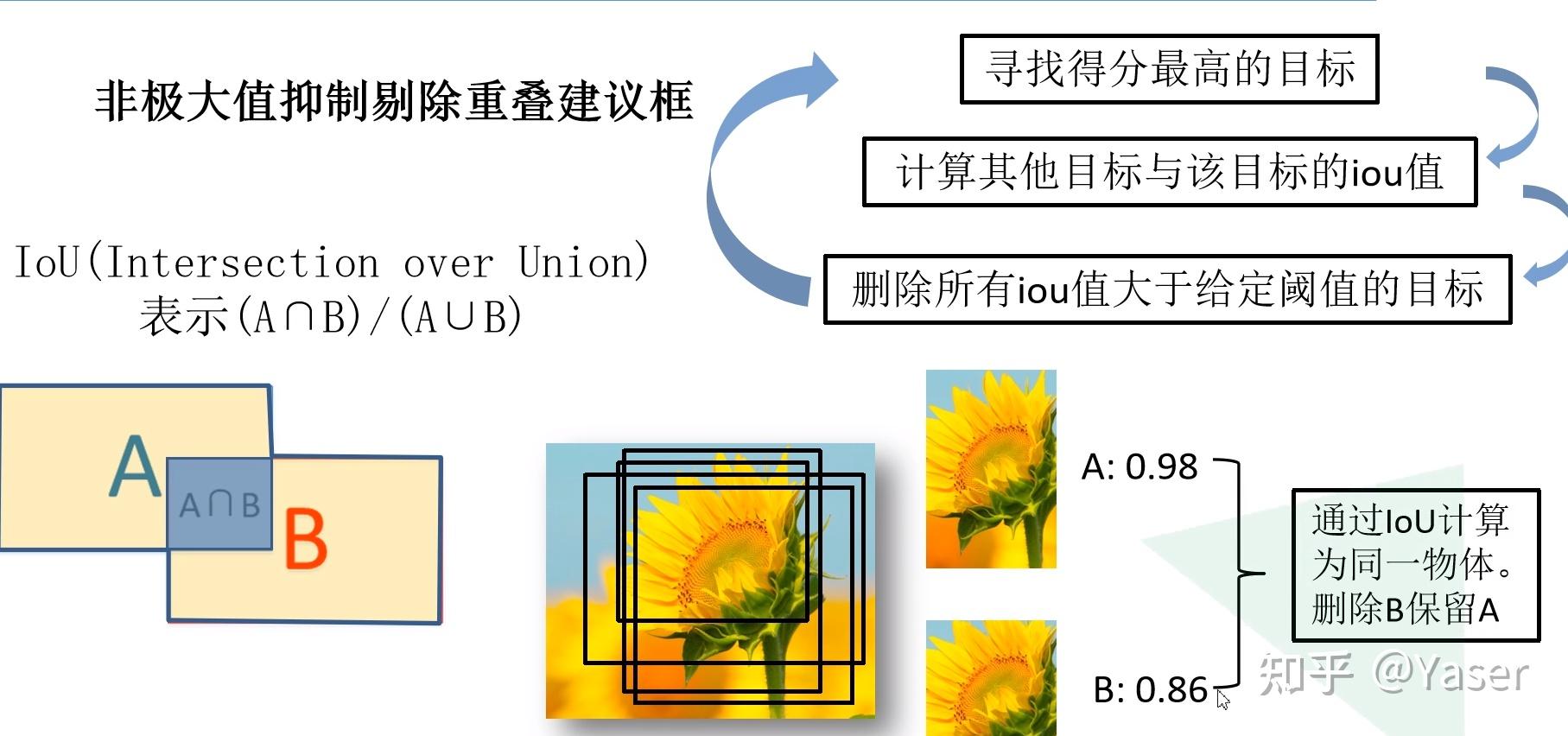
对此,文中选择使用 flow-based 的姿势相似性度量: 
有时候,由于与其他人或物体的闭塞,人经常消失并再次出现。考虑连续的两个帧是不够的,因此我们有基于流的姿势相似性考虑多个帧,通过一个双向队列来进行存储和更新。这样,我们甚至可以重新链接在中间帧中消失的实例。
实验
姿态估计
这部分实验所采用的数据集是COCO,这也是当下比较流行的数据集。
实验一
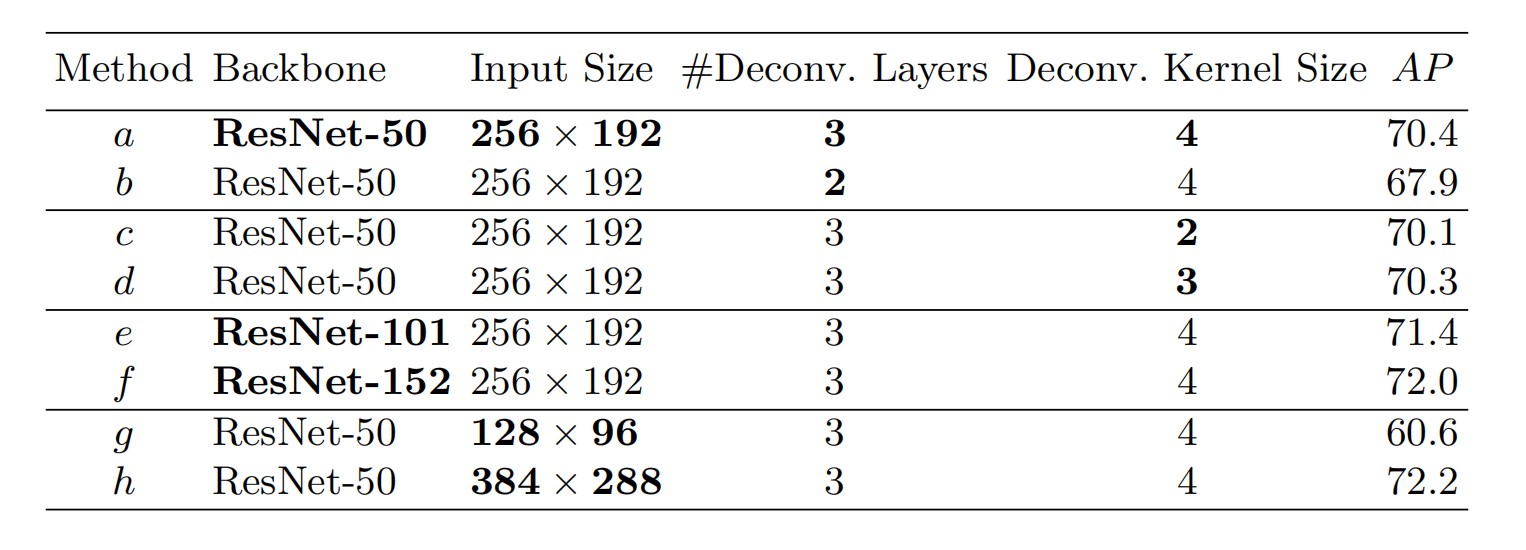
结论:backbone越大,热图的分辨率越大,图像的尺寸越大,卷积核越大,准确率越高,但同样的,计算成本也越高。
实验二
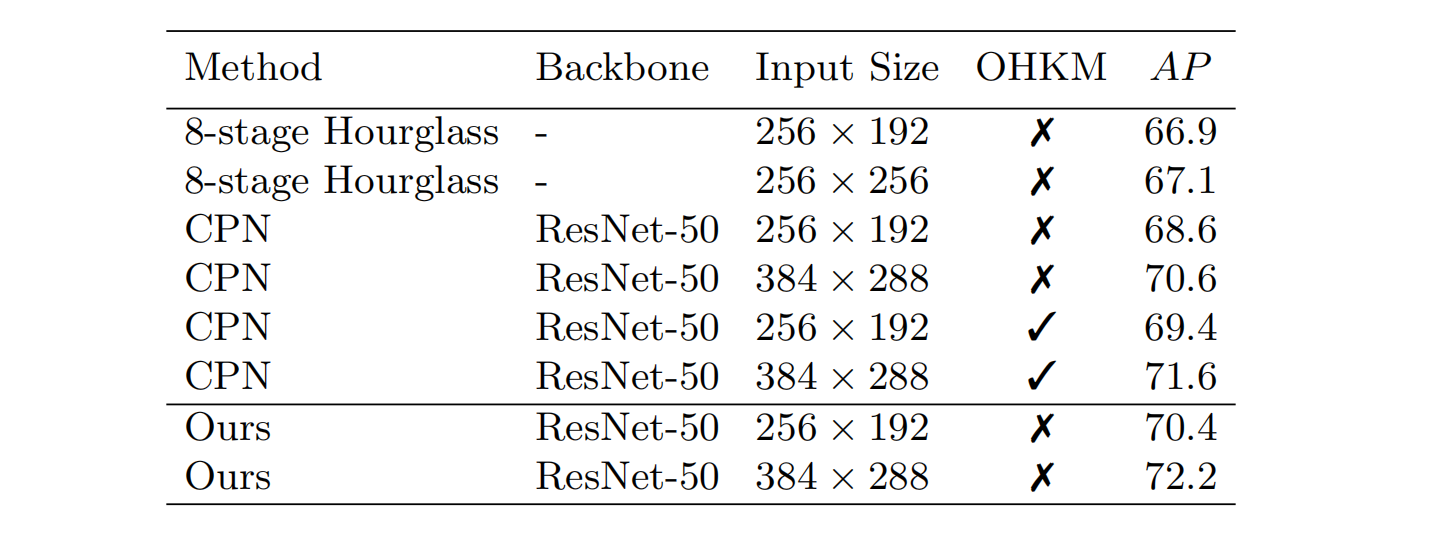
结论:在没有使用 Online Hard Keypoints Mining (OHKM)的情况下,论文中的模型性能是最优的。
PS:OHKM是指对较难的点进行二次检测
实验三
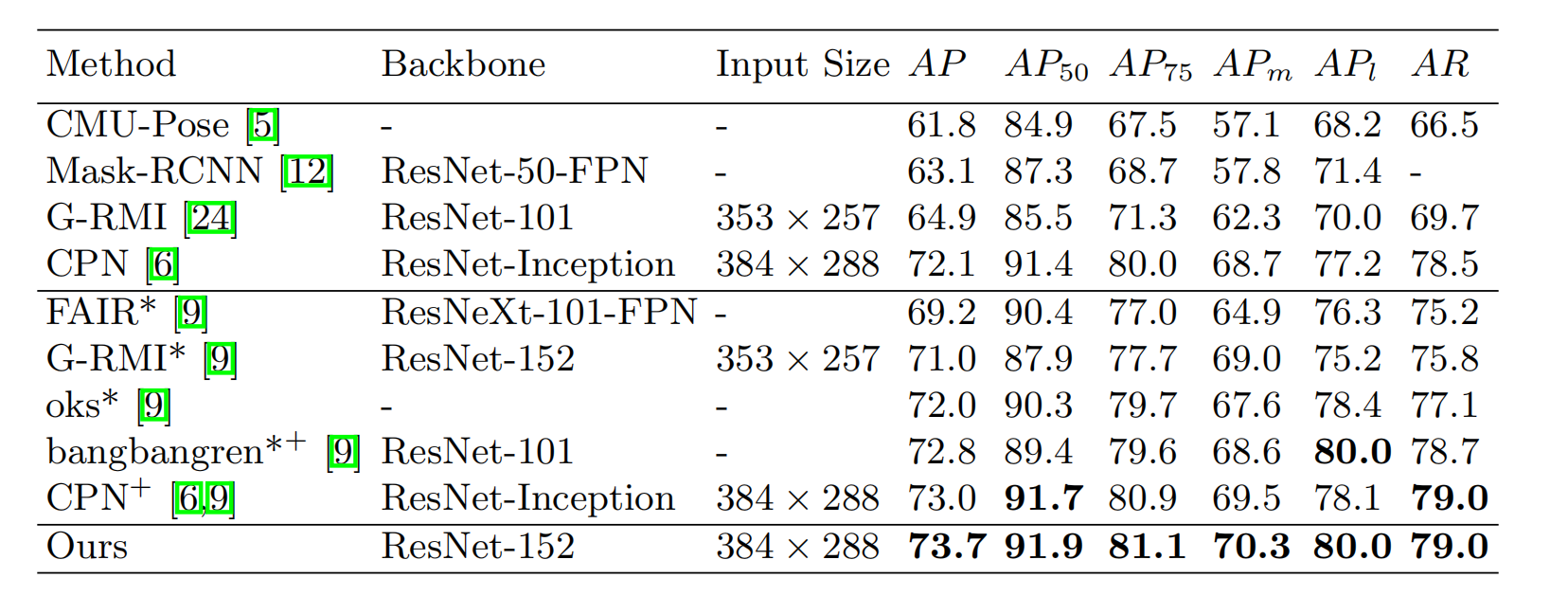
结论:我们的模型虽然简单,但是性能好
姿态追踪
这部分的实验采用的是PoseTrack视频数据集。
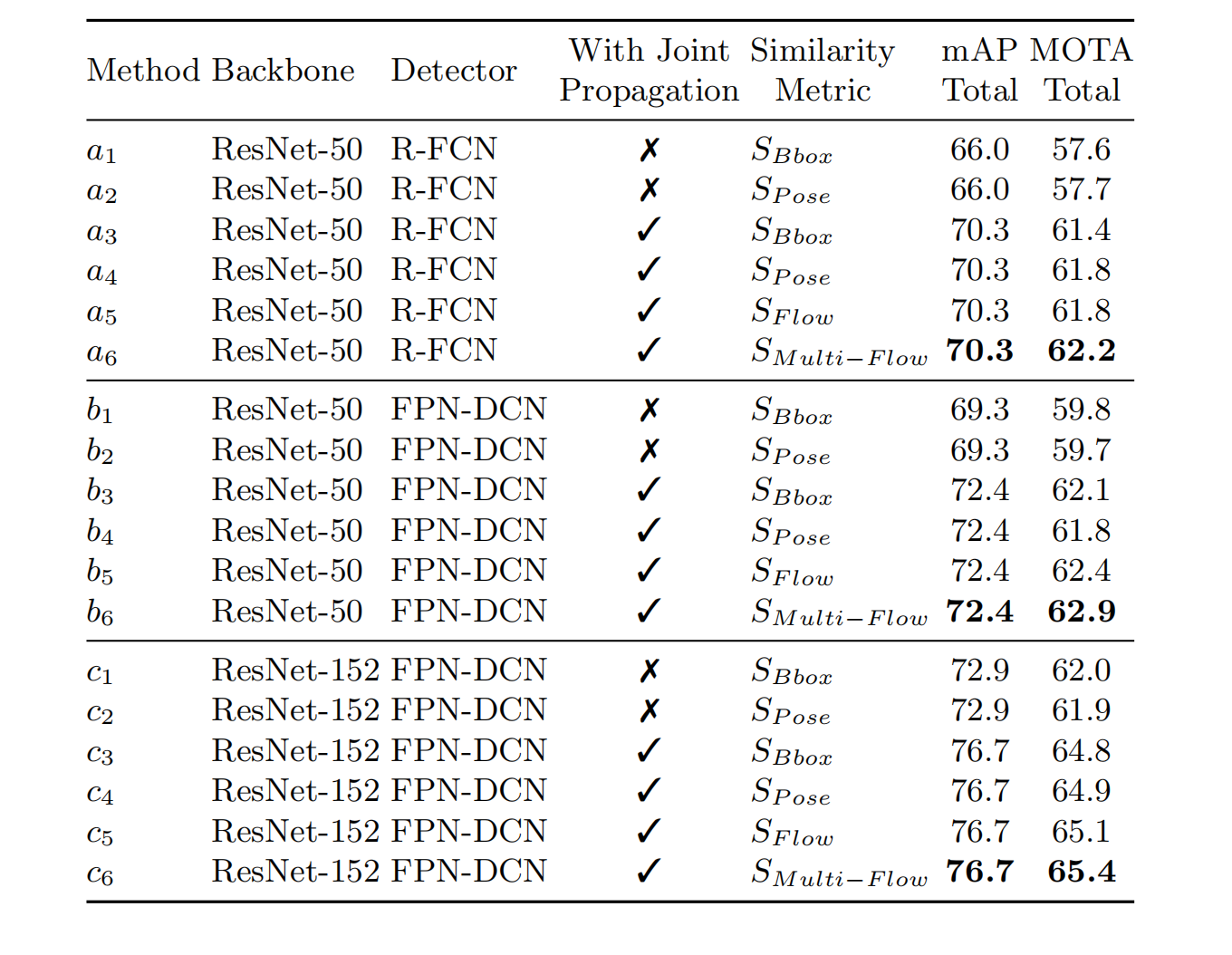
结论:类似的控制变量,模型越大,使用光流和(多帧)姿势相似度会在一定程度上增强模型的性能。
剩下的实验也是说明本文的模型性能较好,于是就不再赘述。
总结
本文提出了姿态估计和姿态追踪领域简洁但是性能强大的baseline。他们在具有挑战性的基准测试上取得了SOTA。通过全面的消融研究证实了这一点。作者也希望这样的基线能够通过简化创意开发和评估,使该领域受益。
