论文阅读-02
这篇是对《Feature Pyramid Networks for Object Detection》这篇论文的阅读和理解笔记,其中不乏疏忽或误解之处,发现者还请指正。
FPN能够很好地处理小目标的主要原因是:
- FPN可以利用经过top-down模型后的那些上下文信息(高层语义信息)
- CNN网络由浅到深,分辨率越来越粗糙,特征图越来越小,因为池化产生的不同尺寸的特征图。但是越高层,语义信息越丰富。相似的思想利用在FCN的自顶向下连接(这边可以跳层连接哦)。也就是要识别多尺度的目标,利用不同尺度的特征图。对于小目标而言,FPN增加了特征映射的分辨率(即在更大的feature map上面进行操作,这样可以获得更多关于小目标的有用信息)
总结来说,FPN = top-down的融合(skip layer) + 在金字塔各层进行prediction。
摘要
目标的多尺度一直是目标检测算法极为棘手的问题。像Fast R-CNN,YOLO这些只是利用深层网络进行检测的算法,是很难把小目标物体检测好的。因为小目标物体本身的像素就比较少,随着降采样的累积,它的特征更容易被丢失。为了解决多尺度检测的问题,传统的方法是使用图像金字塔进行数据扩充。虽然图像金字塔可以一定程度解决小尺度目标检测的问题,但是它最大的问题是带来计算量的极大的增加,而且还有很多冗余的计算。
我们这篇文章要介绍的特征金字塔网络(Feature Pyramid Network,FPN)是一个在特征尺度的金字塔操作,它是通过将自顶向下和自底向上的特征图进行融合来实现特征金字塔操作的。FPN提供的是一个特征融合的机制,并没有引入太多的参数,实现了以增加极小计算代价的情况下提升对多尺度目标的检测能力。
介绍
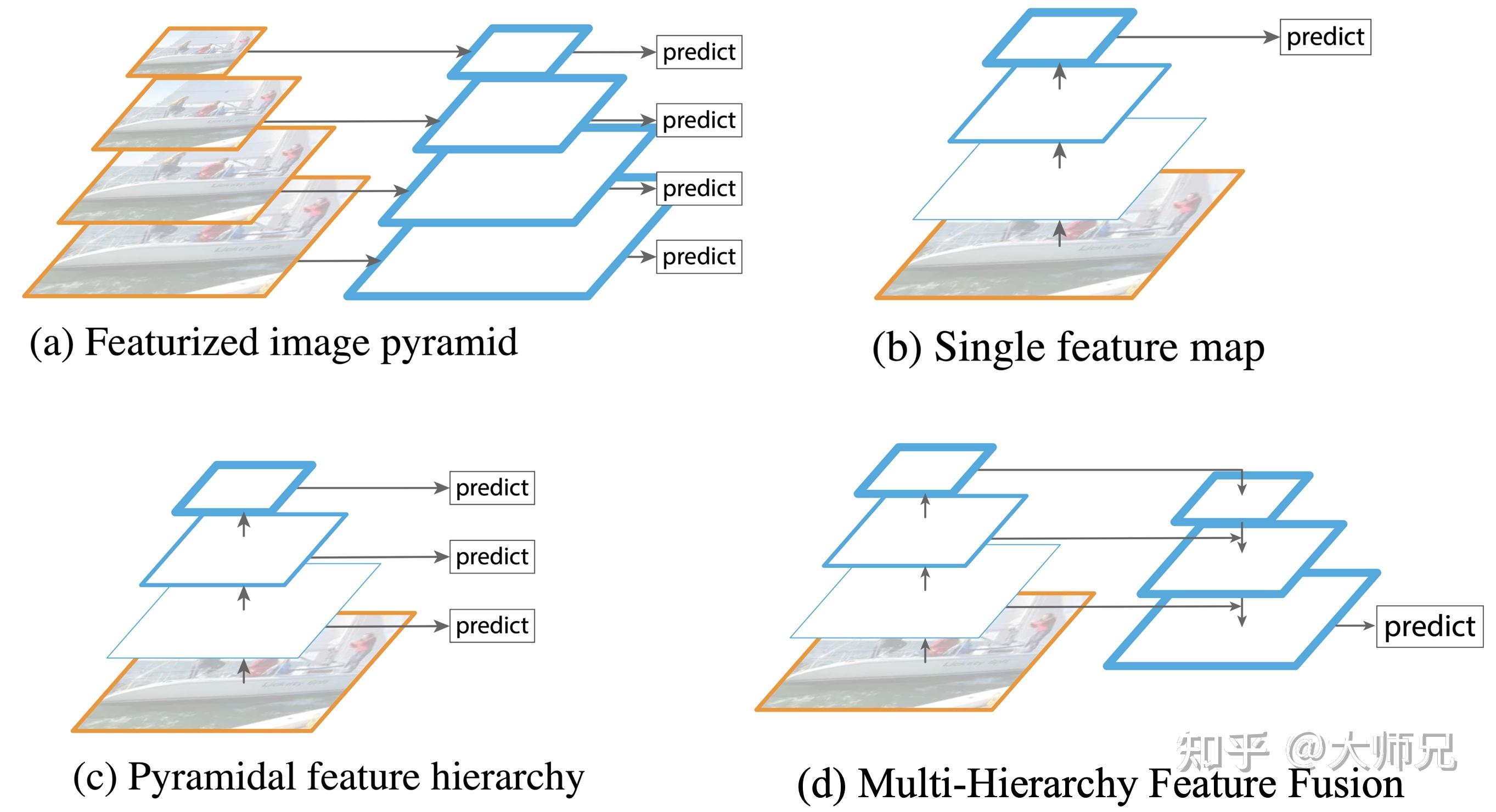
在FPN之前,目标检测主要有4种不同的金字塔结构类型,如图1所示。其中图1.(a)是早期的目标检测算法常用的图像金字塔,它通过将输入图像缩放到不同尺度的大小构成了图像金字塔。然后将这些不同尺度的特征输入到网络中(可以共享参数也可以独立参数),得到每个尺度的检测结果,然后通过NMS等后处理手段进行预测结果的处理。图像金字塔最大的问题是推理速度慢了几倍,一个是因为要推理的图像数多了几倍,另一个原因是要检测小目标势必要放大图像。
图1.(b)是Fast R-CNN,Faster R-CNN,YOLO等算法的网络结构,它只使用卷积网络的最后一层作为输出层。这个结构最大的问题就是对小尺寸的目标检测效果非常不理想。因为小尺寸目标的特征会随着逐层的降采样快速损失,到最后一层已经有很少的特征支持小目标的精准检测了。
图1.(c)是SSD采用的结构,它首先提出了使用不同层的Feature Map进行检测的思想。但是SSD只是单纯的从每一层导出一个预测结果,它并没有进行层之间的特征复用。即没有给高层特征赋予浅层特征擅长检测小目标的能力,也没有给浅层的特征赋予高层捕捉到的语义信息,因此带来的小目标的检测效果的提升是非常有限的。
特征融合在其它模型中也有过探索,例如医学分割算法中的U-Net,如图1.(d)所示。U-Net的特点是只在模型的最后一层进行了预测,并没有使用多分辨率预测。
文中的介绍是按照出现和发展的顺序来的,其中最自然而然出现的便是特征图像金字塔,架构如下:
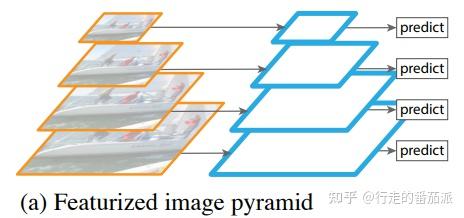
这种架构通过将图片放缩到不同的尺寸,然后对不同的尺寸的图片进行特征提取,然后进行分别进行预测并将结果进行综合。通过这种方式,可以很好的避免图片尺寸带来的问题,同时也能较好的同时检测到跨尺度的特征。但同时,这种方式有着几个比较明显的缺陷:
- 由于每层都要进行完整的计算推理,因此所需要的时间成本大大增加
- 由于一张图片需要存储多个尺度的副本,因此所需要的空间内存成本大大增加
- 训练和使用会存在一定的不确定性
由于以上的一些问题,再加上神经网络的普及,开始出现以卷积为主的网络架构,如下所示:
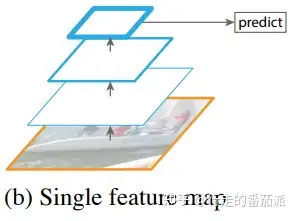
网络中一般通过若干个卷积层后使用最后得到的若干特征进行预测,通过这种方式可以很好的减小计算开销。
但同时,他只使用了最后的富含语义信息的特征,而忽略了前面的浅层信息,这将导致小物体的识别和探测的效果很差。
为此,人们将2者结合起来,构造出特征金字塔:
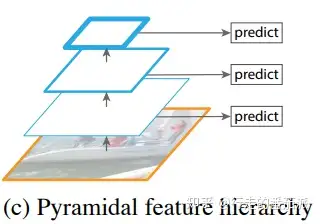
将卷积网络作为主体网络,同时对每次卷积块输出的特征图进行预测,然后将预测结果进行综合。这种方式从网络不同层抽取不同尺寸的特征做预测,没有增加额外的计算量。
但作者认为,这种方式无法充分的使用底层的特征,因此,作者在Unet等网络的基础上,提出特征金字塔网络:对最底层的特征进行向上采样,并与该底层特征进行融合,得到高分辨率、强语义的特征(即加强了特征的提取),架构如下图所示:
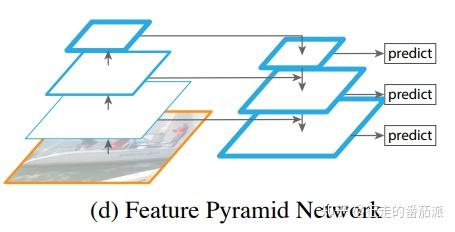
相关工作
相关工作方面也是按照时间的顺序来撰写的,从最开始的手动选择特征,到之后的深度神经网络加RCNN进行识别,再到现在的使用不同尺寸的层协同进行识别,网络的变化也如上面的介绍中所写的类似,这边就不再赘述。
网络细节
FPN的核心思想是把高层的特征传下来,补充低层的语义,这样就可以获得高分辨率、强语义的特征,有利于小目标的检测。其所使用的backbone是ResNet。CNN的前馈计算就是自下而上的路径,特征图经过卷积核计算,通常是越变越小的,也有一些特征层的输出大小和输入大小一样。
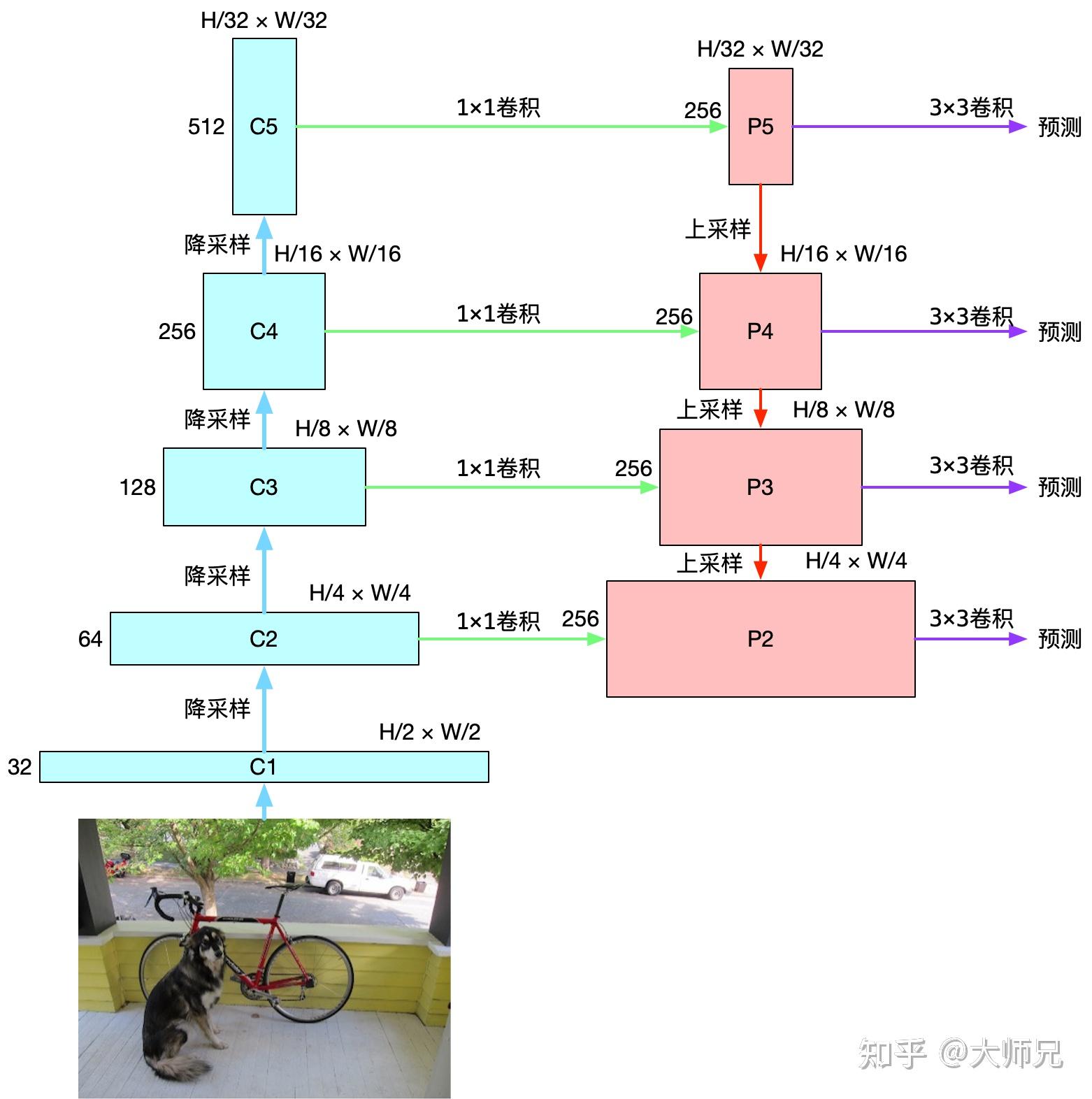
其包含3个主要路线:
自底向上即是卷积网络的前向过程,我们可以选择不同的骨干网络,例如ResNet-50或者ResNet-101。前向网络的返回值依次是C2,C3,C4,C5,是每次池化之后得到的Feature Map。在残差网络中,C2,C3,C4,C5经过的降采样次数分别是2,3,4,5即分别对应原图中的步长分别是4,8,16,32。这里之所以没有使用C1,是考虑到由于C1的尺寸过大,训练过程中会消耗很多的显存。
通过自底向上路径,FPN得到了四组Feature Map。浅层的Feature Map,例如C2含有更多的底层信息(纹理,颜色等),而深层的Feature Map如C5含有更多的语义信息。为了将这四组倾向不同特征的Feature Map组合起来,FPN使用了自顶向下及横向连接的策略,最终得到P2,P3,P4,P5四个输出。
最后,FPN 在 P2,P3,P4,P5 之后均接了一个 3×3 卷积操作,该卷积操作是为了减轻上采样的混叠效应(aliasing effect)。
混叠效应:在统计、信号处理和相关领域中,混叠是指取样信号被还原成连续信号时产生彼此交叠而失真的现象。当混叠发生时,原始信号无法从取样信号还原。而混叠可能发生在时域上,称做时间混叠,或是发生在频域上,被称作空间混叠。在视觉影像的模拟数字转换或音乐信号领域,混叠都是相当重要的议题。因为在做模拟-数字转换时若取样频率选取不当将造成高频信号和低频信号混叠在一起,因此无法完美地重建出原始的信号。为了避免此情形发生,取样前必须先做滤波的操作。
横向连接的主要目的是为了利用底层的定位细节信息(由于底部的feature map包含更多的定位细节,而顶部的feature map包含更多的目标特征信息)中,需要注意的是,两层特征在空间尺寸上要相同,这是通过上采样(插值)来实现的;同时,底部的feature map的通道数可能会出现过多的情况,这时便使用1 * 1 的卷积来减少通道数。
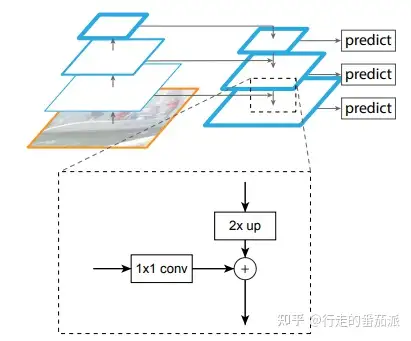
FPN的应用
FPN和U-Net最大的不同是它的多个层级的都会有各自的输出层,而每个输出层都有不同吃的的感受野。一个比较粗暴的方式是每一层都预测所有的样本,而另一个更好的选择是根据一些可能存在的先验知识选择一个最好的层。比较有代表性的有FPN的锚点先验和Fast R-CNN的ROI先验。
总结
FPN是最早在目标检测方向上提出特征融合的算法,开辟了特征融合的先河,为之后PANet,NAS-FPN等算法的提出打下了基础。FPN是一个特征金字塔的结构。FPN的这种特征金字塔的结构是非常符合CNN的结构特征的,通过将深层语义信息和浅层纹理信息进行融合,为每一层的Feature Map都赋予了更强的捕捉语义信息的能力。
这里FPN也有几个不足:
- 使用了最近邻居采样,这个采样方式略显粗糙,而双线性差值或者反卷积的上采样方式更加合理;
- FPN的自底向上的融合方式略微简单,知识将高层的语义信息传递到低层,而低层的纹理信息并没有传递到搞成。

