论文阅读-03
这篇是对《Training data-efficient image transformers & distillation through attention》这篇论文的阅读和理解笔记,其中不乏疏忽或误解之处,发现者还请指正。
摘要
DeiT 是一个全 Transformer 的架构。其核心是提出了针对 ViT 的教师-学生蒸馏训练策略,并提出了 token-based distillation 方法,使得 Transformer 在视觉领域训练得又快又好。
介绍
经典模型 ViT 的缺点和局限性
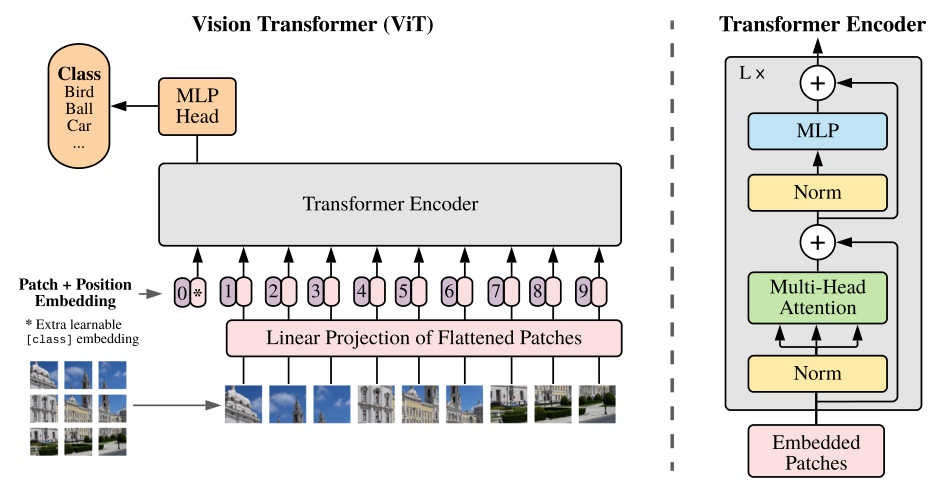
使用Transformer结构完成视觉任务的典型的例子比如说 ViT 。Transformer的输入是一个序列 (Sequence),那么现在我们有的是一堆图片,如何转成序列呢?ViT所采用的思路是把图像分块 (patches),然后把每一块视为一个向量 (vector),所有的向量并在一起就成为了一个序列 (Sequence),ViT使用的数据集包括了一个巨大的包含了300 million images的JFT-300,这个数据集是私有的,即外部研究者无法复现实验。而且在ViT的实验中作者明确地提到:
" that transformers do not generalize well when trained on insufficient amounts of data. "
意思是当不使用JFT-300这样子的巨大的数据集时,效果是不如CNN模型的,也就反映出Transformer结构若想取得理想的性能和泛化能力就需要这样大的数据集。但是普通的研究者一没有如此extensive的计算资源,而没有如此巨大的数据集,所以无法复现对应的实验结果,这也是这篇文章 (DeiT) 的motivation。简而言之,作者通过所提出的训练方案。只在 Imagenet 上进行训练,就产生了一个有竞争力的无卷积 transformers,而且在单台计算机上训练它的时间不到 3 天。DeiT (86M参数)在 ImageNet 上实现了 83.1% 的 top-1 精度。
Data-efficient image Transformers (DeiT) 的优势
- DeiT只需要8块GPUs训练2-3天 (53 hours train,20 hours finetune)。
- 数据集只使用 ImageNet。
- 不包含任何卷积 (Convolution)。
这篇文章的主要贡献可以总结为三点:
- 仅使用 Transformer,不引入 Conv 的情况下也能达到 SOTA 效果。
- 提出了基于 token 蒸馏的策略,针对 Transformer 蒸馏方法超越传统蒸馏方法。
- DeiT 发现使用 Convnet 作为教师网络能够比使用 Transformer 架构效果更好。
相关工作
ViT
transformer架构开始逐渐使用于CV领域。
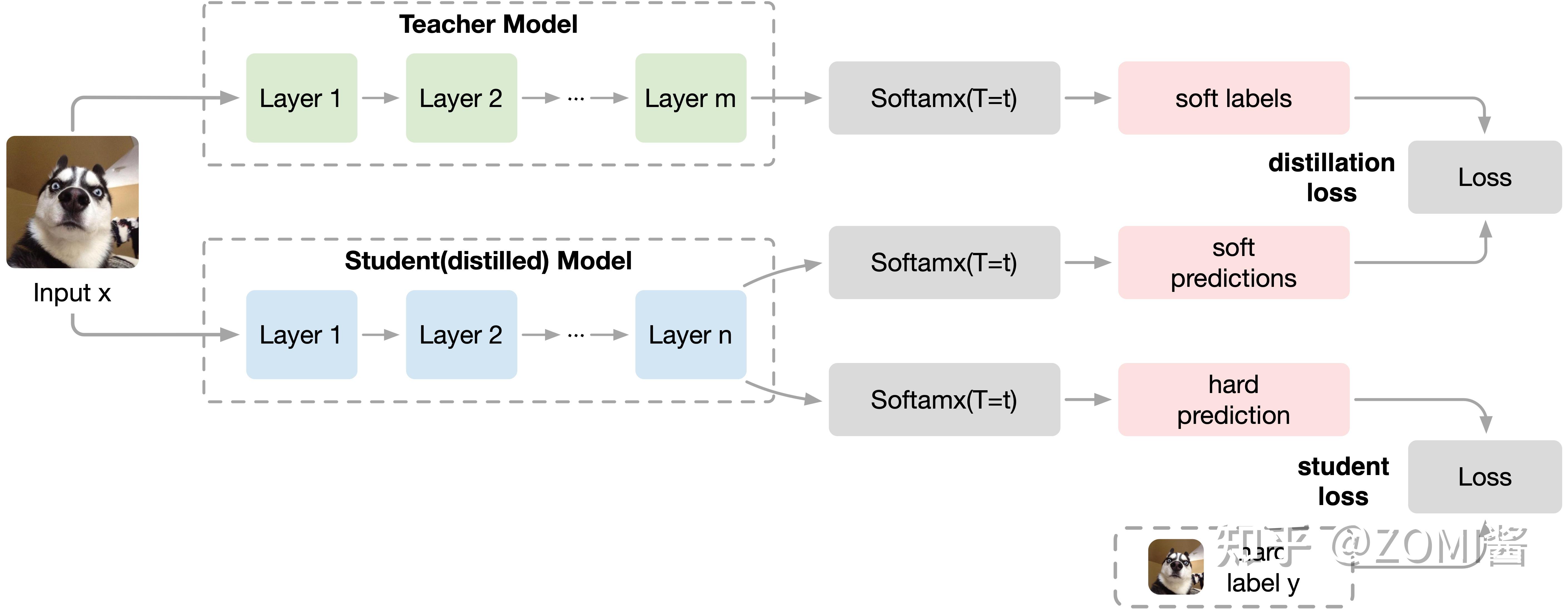
KD
KD方法是一种模型压缩方法,是一种基于“教师-学生网络思想”的训练方式,由于其简单,有效,并且已经在工业界被广泛应用。

模型架构
distillation token 允许我们的模型从教师网络的输出中学习,就像在常规的蒸馏中一样,同时也作为一种对class token的补充。
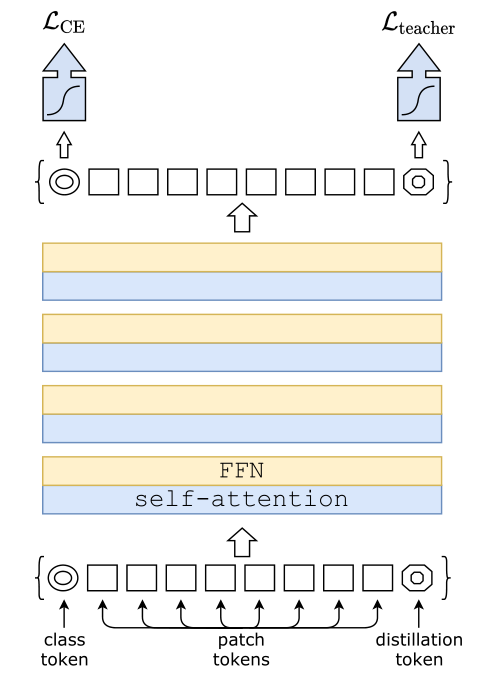
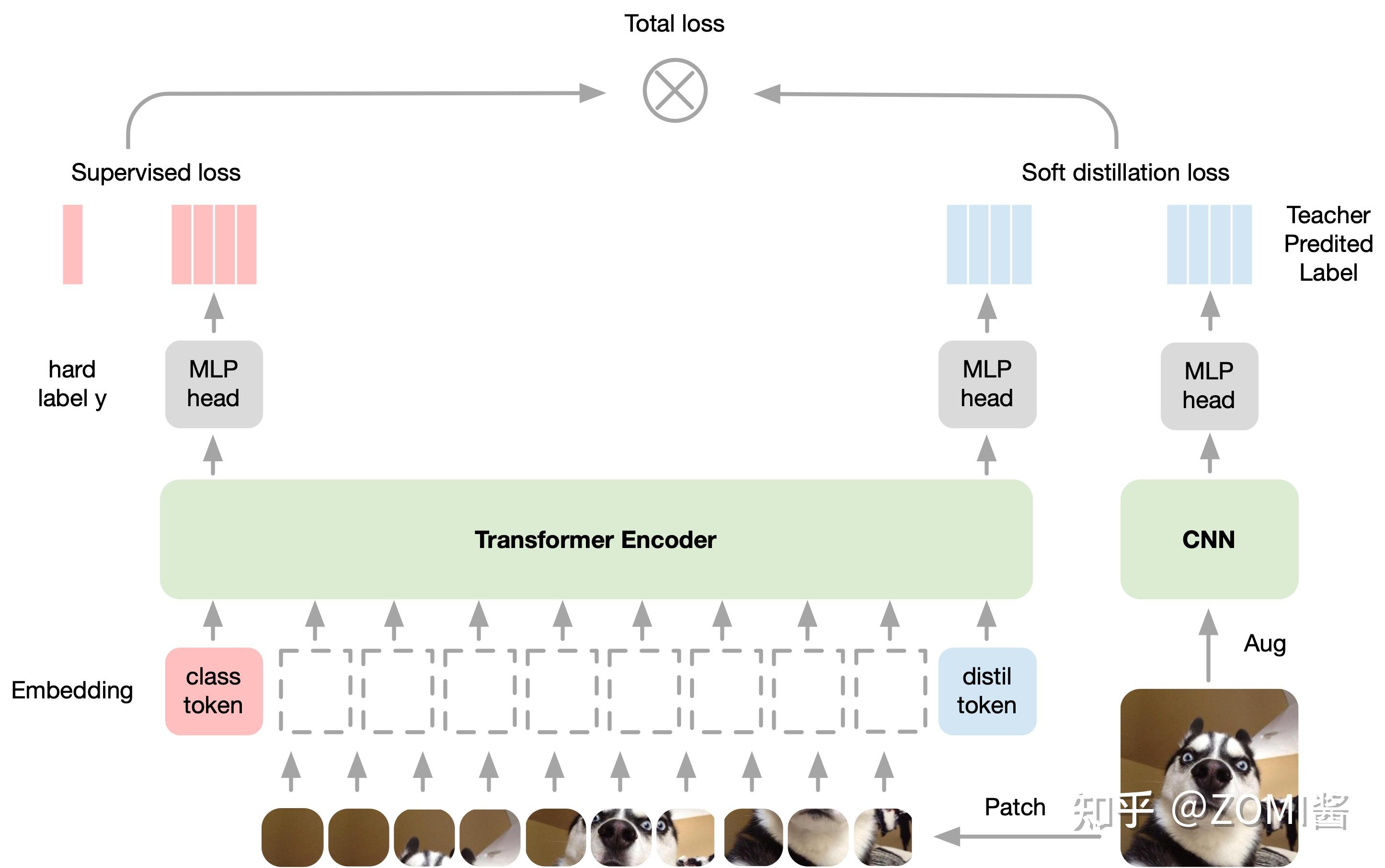
上面的图可以再细化为以下的图:
作者发现一个有趣的现象,class token和distillation token是朝着不同的方向收敛的,对各个layer的这两个token计算余弦相似度,平均值只有0.06,不过随着网络会越来越大,在最后一层是0.93,也就是相似但不相同。 这是预料之中的,因为他们的目标是生产相似但不相同的目标。
作者做了个实验来验证这个确实distillation token有给模型add something。就是简单地增加一个class token来代替distillation token,然后发现,即使对这两个class token进行独立的随机初始化,它们最终会收敛到同一个向量 (余弦相似度为0.999),且性能没有明显提升。
在测试时,我们有class token的输出向量,有distillation token的输出向量,它们经过linear层都可以转化成预测结果,那么最终的预测结果怎么定呢?可以简单地把二者的softmax结果相加来得到预测结果。
实验
与以前看过的论文不同,这篇论文的实验篇幅特别长,占到了一半以上(可能是想掩盖创新点不足?🤔️)
Teacher model对比
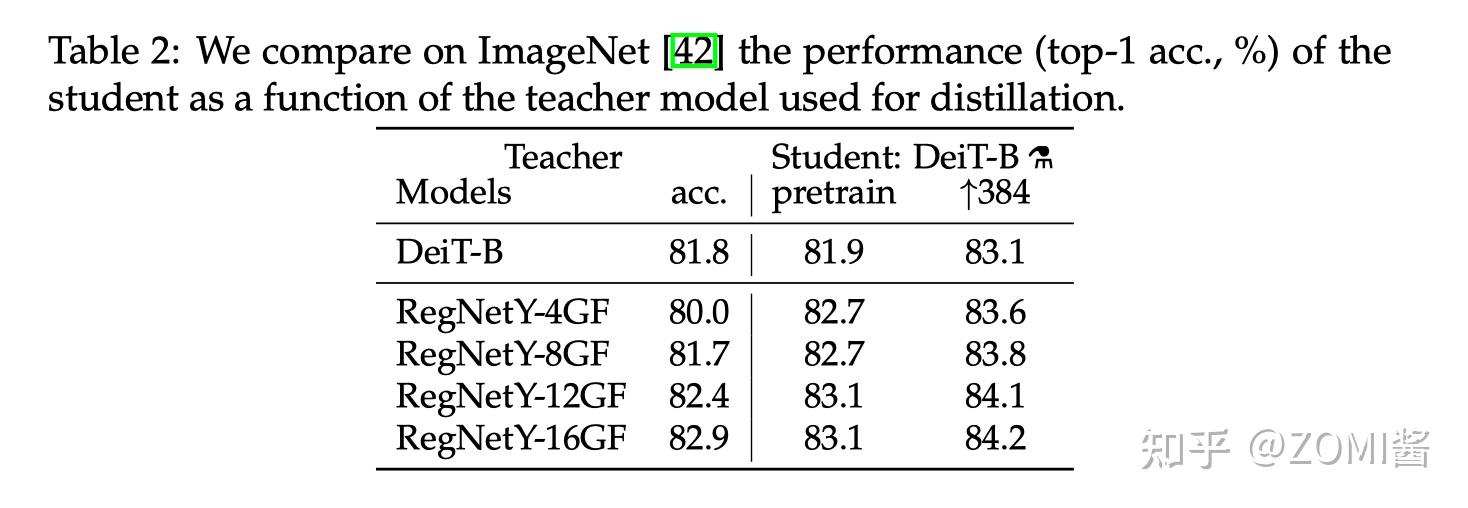
作者首先观察到使用 CNN 作为 teacher 比 transformer 作为 teacher 的性能更优。下图中对比了 teacher 网络使用 DeiT-B 和几个 CNN 模型 RegNetY 时,得到的 student 网络的预训练性能以及 finetune 之后的性能。
其中,DeiT-B 384 代表使用分辨率为 384×384 的图像 finetune 得到的模型,最后的那个小蒸馏符号 alembic sign 代表蒸馏以后得到的模型。
蒸馏方法对比
下图是不同蒸馏策略的性能对比,label 代表有监督学习,前3行分别是不使用蒸馏,使用soft蒸馏和使用hard蒸馏的性能对比。前3行不使用 Distillation Token 进行训练,只是相当于在原来 ViT 的基础上给损失函数加上了蒸馏部分。
对于Transformer来讲,硬蒸馏的性能明显优于软蒸馏,即使只使用 class token,不使用 distill token,硬蒸馏达到 83.0%,而软蒸馏的精度为 81.8%。
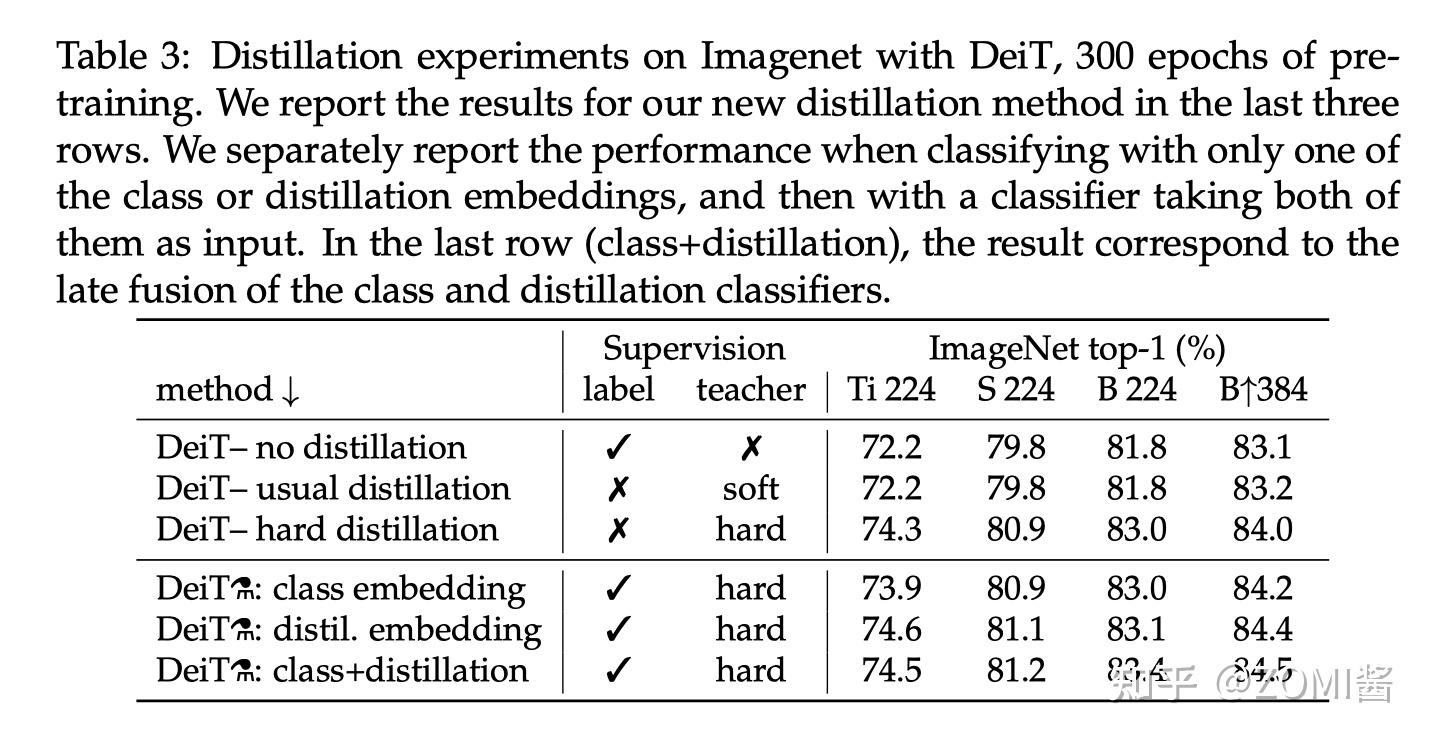
从最后两列 B224 和 B384 看出,以更高的分辨率进行微调有助于减少方法之间的差异。这可能是因为在微调时,作者不使用教师信息。随着微调,class token 和 Distillation Token 之间的相关性略有增加。
除此之外,蒸馏模型在 accuracy 和 throughput 之间的 trade-off 甚至优于 teacher 模型,这也反映了蒸馏的有趣之处。
学习情况
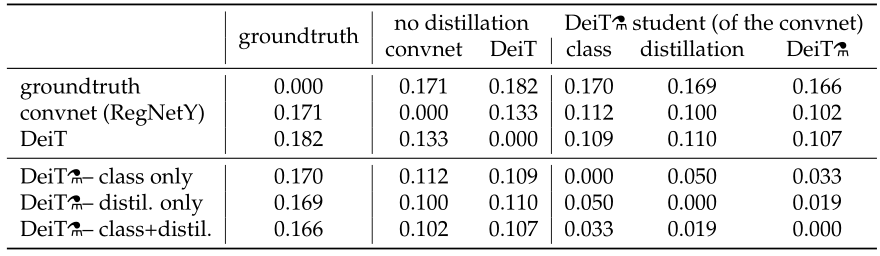
作者分析了一下蒸馏前的DeiT,CNN teacher和蒸馏后的DeiT之间决策的不一致性。如图11所示,6行6列。行列交叉值为行列这2个设置之间决策的不一致性。用distillation token分类的DeiT与CNN的不一致性比用class token的更小,不出意外地,两个都用的DeiT居中。通过第2行可知,蒸馏后的DeiT与CNN的不一致性比蒸馏前的DeiT更小。
性能对比
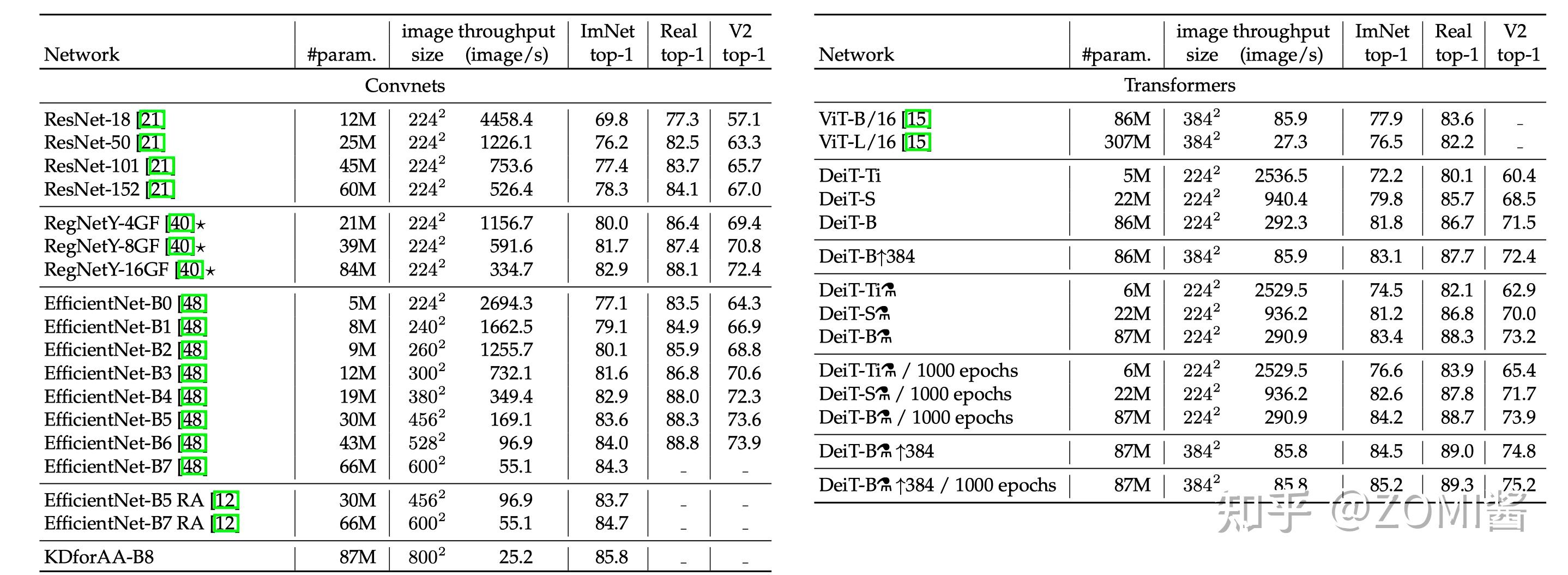
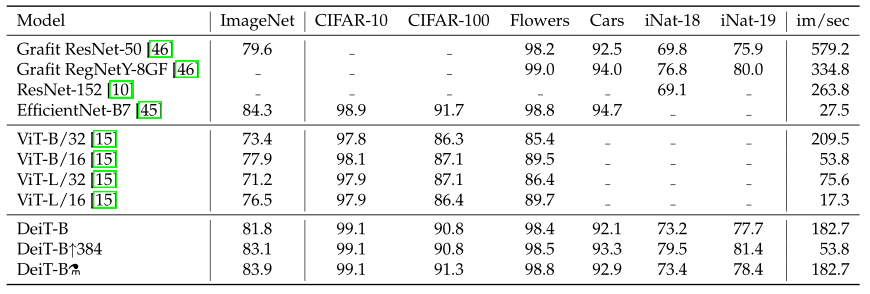
如上图所示为不同模型性能的数值比较。
迁移学习性能
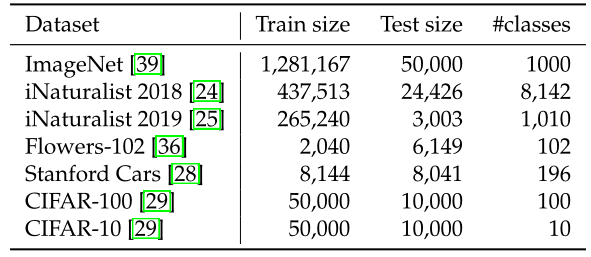
下图一所示为不同任务的数据集,图二为DeiT迁移到不同任务的性能,即不同模型迁移学习的能力对比,对比的所有模型均使用ImageNet作为预训练,包括一些CNN模型。
对比实验和超参数
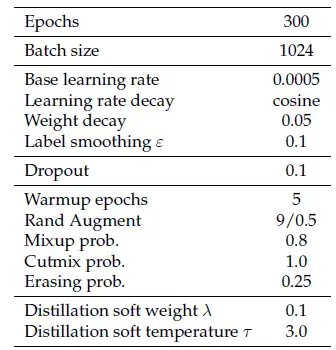
DeiT为我们提供了一组优秀的超参数,如下图所示。它可以在不改变ViT模型结构的前提下实现涨点。
给出了一些个数据增强的方法:

mixup之后的图片的label不再是单一的label,而是soft-label,比如[cat,dog]=[0.5,0.5]
cutmix之后的图片label是按所占据的比例给的,比如[cat,dog]=[0.3,0.7]
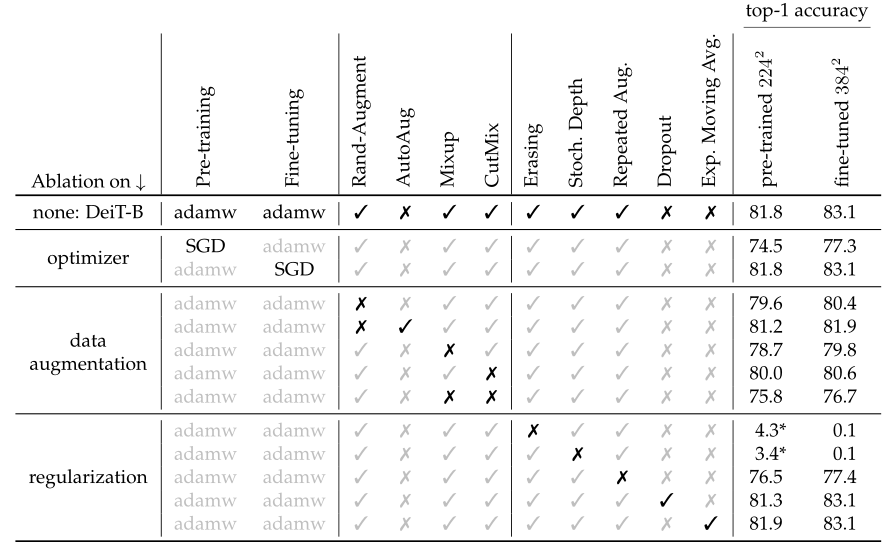
下图就是一些个对比实验
总结
DeiT 模型(8600万参数)仅用一台 GPU 服务器在 53 hours train,20 hours finetune,仅使用 ImageNet 就达到了 84.2 top-1 准确性,而无需使用任何外部数据进行训练,性能与最先进的卷积神经网络(CNN)可以抗衡。其核心是提出了针对 ViT 的教师-学生蒸馏训练策略,并提出了 token-based distillation 方法,使得 Transformer 在视觉领域训练得又快又好。

